Lecture notes of LSTM's Inventor Sepp Hochreiter
Sepp Hochreiter was graduated from Technische Universität München, LSTM was invented when he was in TU and now he is the head of Institute of Bioinformatics, Johannes Kepler University Linz.
Today he comes by Munich and gives a lecture in Fakultät Informatik.
At first, Hochreiter praised how hot is Deep Learning (to be referred as DL) around the world these days, especially LSTM, which is now used in the new version of google translate published a few days ago. The improvements DL made in the fields of vision and NLP are very impressive.
Then he starts to tell the magic of DL, taking face recognition as an example, the so-called CNN (Convolution Neuro Networks):
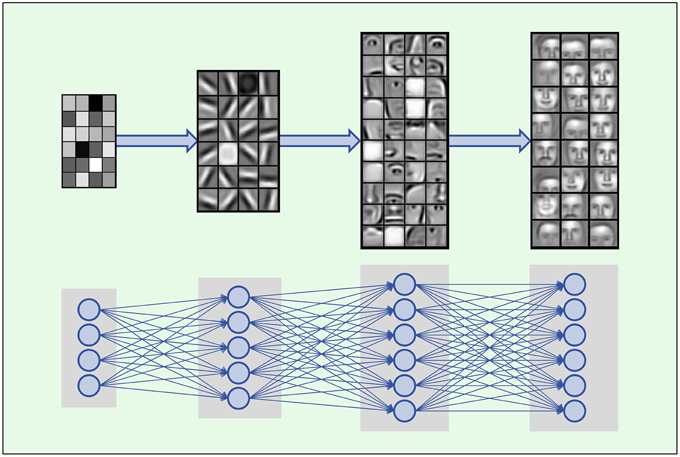
This is a commonly used case, input layer is pixels, the output of the first layer will be the edges and corners, the second layer will output some local structures such as nose, eyes and ears, the last layer will output a part of a whole face.
Then he explained a case which is not very commonly used: using DL to look for drugs.
The first layer will output some chemical radicals, such as hydroxyl and carboxyl
The second layer will output the interaction centre
The third layer will output pharmacophore, which is biologically active and can then be used to design drugs.
The next topic is Vanishing Gradient Problem
In the back-propagation algorithm, we compute the gradient on each neurone and multiply them using the chain rule, for the neighbouring update value we have:
\[\sigma^{i-1}=\sigma^i\cdot J^i\]\(\sigma^i\) is the update value of the \(i\)th layer,\(J^i\) is the jacobian matrix of the \(i\)th layer, which is also the gradient, then we get the update for the 1st layer:
\[\sigma^1=\sigma^T \prod_i J_i\]\(T\) is the total amount of layers, at same time, we also know that:
\[\| J_i\| \leqslant k <1\]So when \(T\) is big (In DL there will always be a lot of layers):
\[\| \sigma^1\|=\|\sigma^T \prod_i J_i\|\approx0\]We can see that the closer to the 1st layer, the smaller is the update value, when the depth of DL gets big, we can hardly update the layers close to the 1st layer, which means we can not train the DL network.
This is the always existed barrier for using the deep network.
The solutions for this problem are:
ReLU:take a look at my blog NN: one neurone
LSTM:control the gradient
High way nets
Residual nets
Hochreiter said that he is now working on the so-called Self-normalization Neuro Network, it can be used to construct massive AI system such as home service robot, a robot for Mars landing.
Then he begins to talk about some cases
The first case is German shopping website Zalando, Zalando hope to follow the fashion from learning fashion blogs with DL by analysing the texts and images to recommend customers products. The recommendation will be different from the location, the customers from Milan and San Francisco will see different product recommendations, as different cities have different taste, which means they will trace the local fashion hotspot. One picture gets a lot of likes, then we need to analyse why? And then recommend you products.
Another good thing for LSTM is Uniform Credit Assignment
It means for the information we want to get, wherever it is located, the algorithm will assign the same credit(importance) for it.
Take the following 3 sentences as an example:
One man is running, he wears a red jack.
One man in red jack is running.
A red jack wears on a running man.
The same information “man running” in these 3 sentences will get the same credit.
Because LSTM can save the memory, it keeps what you have seen, it keeps ideas, situations.
This speciality is very useful when dealing with videos, because in some situation you can not see a lot from one single image, you should check the video. For example, one man riding a bike is waving his left hands to turn left.
Assume that at \(t_1\) he is waving his left hand, put it down at \(t_2\) and turn left really at \(t_3\).
If we only look at the image at \(t_3\), it is too difficult for us to predict which direction is the riding man turn to. But combining the previous memory, we know that he is turning left, at this moment LSTM shows its advantage.
Another hotspot is Attention, in one video, if the car is important, we put more attention on the car.
Image classification (caption) problem:
CNN input a set of images, the output will be a Meaning Pool.
RNN input a sequence of images, the output will be a Meaning Sequence, which means when we input one image, we will get a new meaning(caption).
Then he referred a Zalando’s advertisement to talk about DL’s drawbacks:

The two red shoes on the girl’s hands will be captioned as red wine, wrongly. Why? Because in the images of the training set, the red things on someone’s hand are mostly red wine, what’s more, the shoes in the training images are mostly worn by someone, on the ground, so a pair of red shoes in the hands will be assigned a very probability to be shoes.
In order to conquer this drawback, a very large training set is needed, that’s why we name it “big data” .
But how can we get so many data? Taking auto drive as an example, we can found a “Kindergarten” for cars and let them learn by their selves.
Another problem is sometimes the images are classified correctly wrongly.
What does that mean?
For example in the competition of ImageNets, someone wants to classify an image, showing two people playing ping-pong ball, he classified the image to “ping-pong ball” correctly.
But the ping-pong ball in this image is flying very fast and its shape is stretched, which is astonishingly classified as “ping-pong ball” correctly. Does it mean that his algorithm is very good and robust? Not really, the reason that his algorithm classified the image to “ping-pong ball” is not because it recognise the stretched ball but simply it recognised the ping-pong table in the image.
Which means, for the training set, we only provide the class(caption) of “ping-pong ball” but not “ping-pong table”. But both of the ball and tables always appear at the same time, the training algorithm considers the content of table as a ball. Then we can imagine that if we want the algorithm to classify an image showing a man is playing ping-pong against the wall, it will fail.
The last stage: Q&A, most of the questions are boring
Someone asked: can we understand the intermedial results of the deep nets?
Hochreiter answered: no, I tried for months to understand the intermedial output, I can understand few things but I can not understand most of the information, we human are just too stupid.
Someone asked: are you afraid that AI will enslave human?
Hochreiter answered: you are dreaming, enslaving human with such simple equations? That’s too far away, we know nothing about our brain.
That’s all I recorded, after finish enjoying the free drinks and pizza, I returned home.
